Bootstrap paramétrico
El bootstrap paramétrico asume que los datos provienen de una familia distribucional específica (normal, exponencial, Poisson, etc.), ajusta esa distribución a los datos y genera muestras bootstrap simulando a partir del modelo ajustado. Cuando el modelo está correctamente especificado, es más eficiente que el bootstrap no paramétrico. Cuando el modelo es incorrecto, los resultados pueden ser engañosos.
Algoritmo
Dada una muestra original \(\mathbf{x} = (x_1, \ldots, x_n)\) y una familia paramétrica asumida \(F_\theta\):
- Ajusta el modelo: estima \(\hat{\theta}\) a partir de los datos, típicamente por máxima verosimilitud.
- Simula: genera \(B\) muestras bootstrap de tamaño \(n\) extrayendo de \(F_{\hat{\theta}}\).
- Reajusta: para cada muestra bootstrap \(\mathbf{x}^*_b\), reestima \(\hat{\theta}^*_b\).
- Resume: usa la distribución de \(\hat{\theta}^*_b\) para estimar la distribución muestral de \(\hat{\theta}\).
\[\mathbf{x}^*_b \sim F_{\hat{\theta}}, \quad b = 1, \ldots, B\]
La diferencia clave respecto al bootstrap no paramétrico: las remuestras se extraen de la distribución paramétrica ajustada \(F_{\hat{\theta}}\), no de la distribución empírica \(\hat{F}_n\).
Bootstrap paramétrico vs no paramétrico
| Paramétrico | No paramétrico (uniforme) | |
|---|---|---|
| Remuestrea de | \(F_{\hat{\theta}}\) (modelo ajustado) | \(\hat{F}_n\) (distribución empírica) |
| Requiere supuesto distribucional | Sí | No |
| Eficiencia cuando el modelo es correcto | Mayor | Menor |
| Robustez cuando el modelo es incorrecto | Escasa | Buena |
| Adecuado para \(n\) pequeño | Sí (si el modelo es correcto) | Moderada |
| Casos de uso habituales | GLM, modelos de supervivencia, series temporales | Cualquier estadístico, análisis robusto |
El bootstrap paramétrico es más eficiente porque usa toda la estructura impuesta por el modelo: las muestras simuladas siguen exactamente la distribución asumida, no la distribución empírica ruidosa. Si el modelo es correcto, esto reduce la varianza de Monte Carlo. Si el modelo es incorrecto, la distribución bootstrap refleja el proceso generador de datos equivocado.
Ejemplos
Ejemplo 1: distribución exponencial
El tiempo entre peticiones a un servidor sigue una distribución exponencial con tasa desconocida \(\lambda\). A partir de \(n = 25\) observaciones, \(\hat{\lambda} = 1/\bar{x} = 0{,}42\) (MLE). Estima el EE de \(\hat{\lambda}\) y compara el bootstrap paramétrico con el no paramétrico.
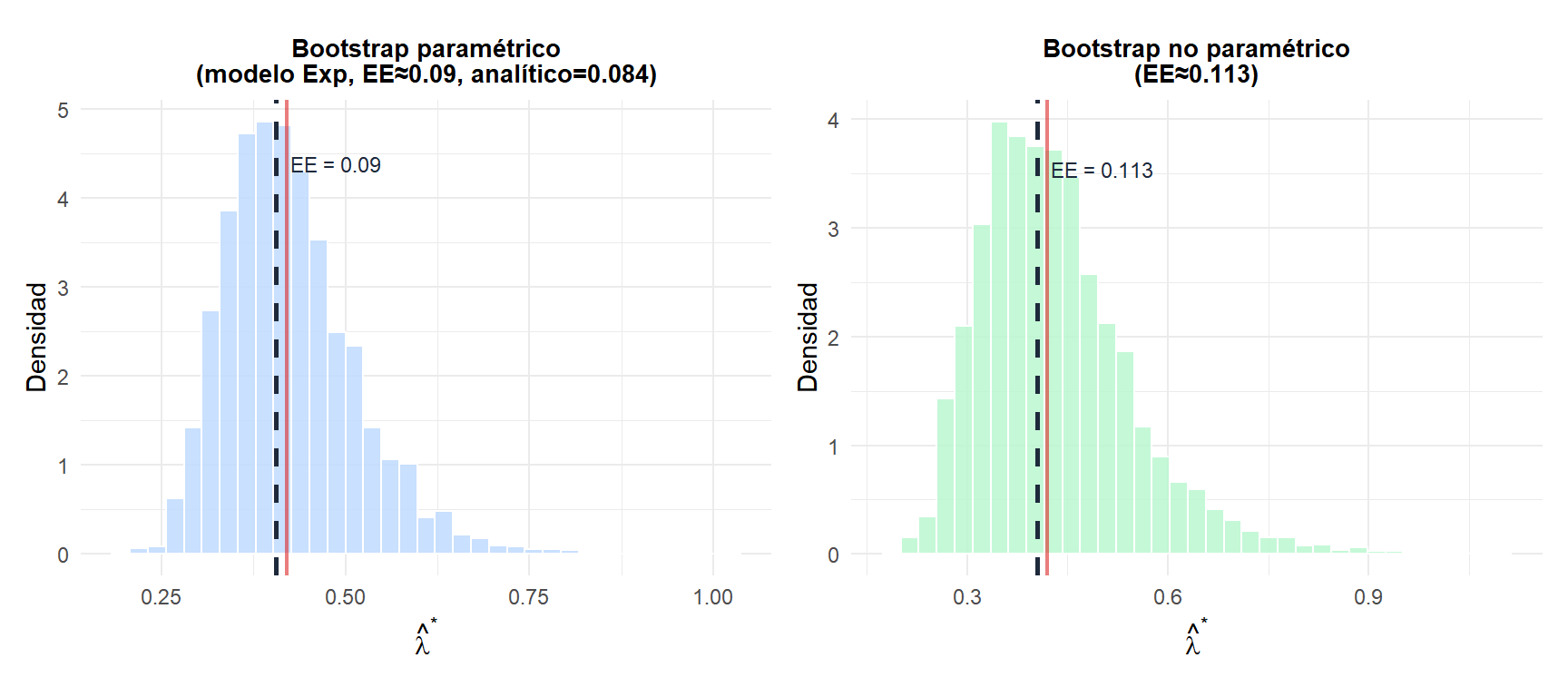
El bootstrap paramétrico (izquierda) produce una distribución más estrecha y suave, más próxima al EE analítico, porque aprovecha la estructura exponencial. El bootstrap no paramétrico (derecha) es más amplio: no hace ningún supuesto distribucional y por tanto tiene mayor varianza de Monte Carlo. La línea roja muestra el verdadero \(\lambda = 0{,}42\).
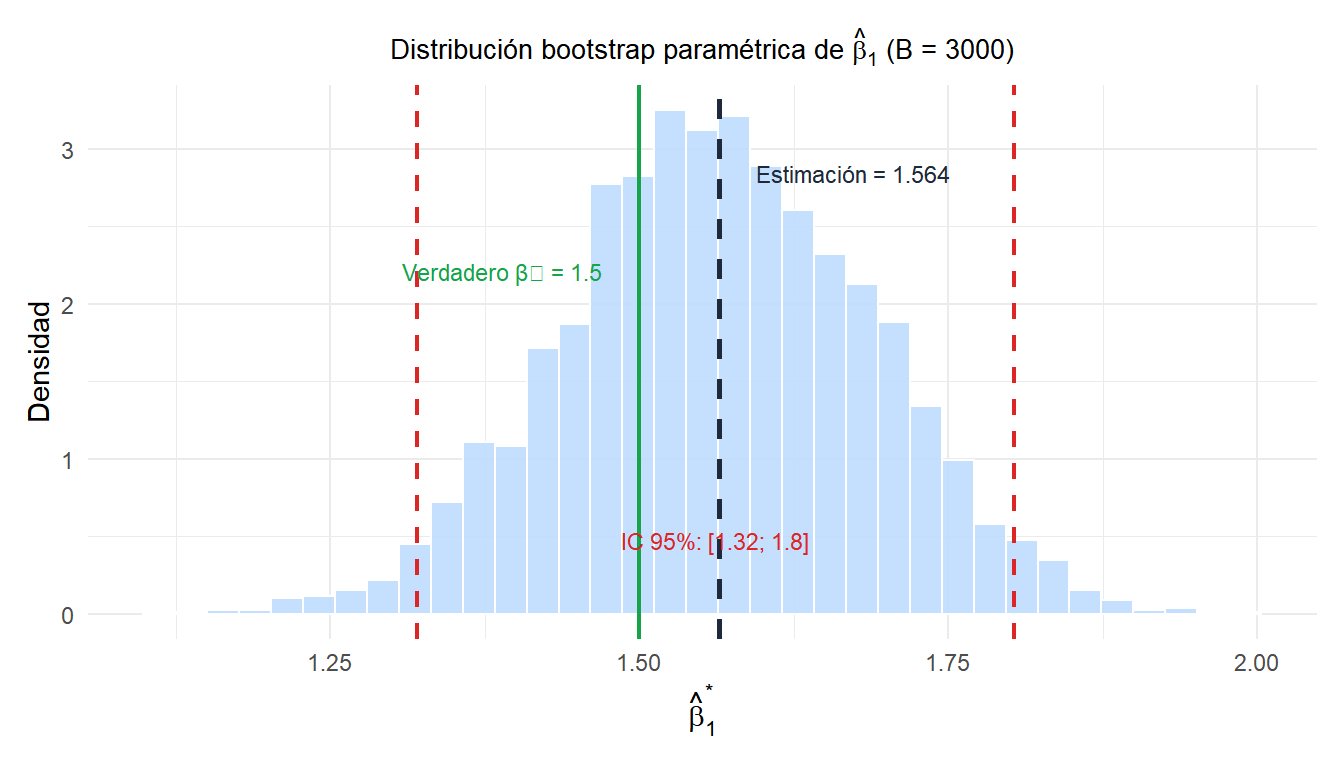
Ejemplo 2: bootstrap paramétrico para un modelo de regresión
En regresión, el bootstrap paramétrico ajusta el modelo y luego simula nuevos valores de la respuesta a partir de la distribución ajustada:
\[y_i^* = \hat{\beta}_0 + \hat{\beta}_1 x_i + \varepsilon_i^*, \qquad \varepsilon_i^* \sim N(0, \hat{\sigma}^2)\]
Esto genera conjuntos de datos bootstrap fijando la matriz de diseño \(X\) y simulando nuevos errores de \(N(0, \hat{\sigma}^2)\). El modelo se reajusta a cada conjunto de datos bootstrap para obtener \(\hat{\beta}^*_b\).
Mala especificación del modelo
⚠️ Un modelo incorrecto produce distribuciones bootstrap incorrectas
El bootstrap paramétrico solo es válido cuando la familia distribucional asumida es correcta. Si se ajusta una distribución normal a datos con asimetría positiva y se usa el bootstrap paramétrico, las muestras simuladas serán simétricas mientras que el verdadero proceso generador de datos es asimétrico. El EE y el IC bootstrap resultantes serán incorrectos.
Señales de mala especificación que conviene comprobar antes de usar el bootstrap paramétrico:
- Gráfico Q-Q: los puntos deben seguir la diagonal para la distribución asumida.
- Test de bondad de ajuste: Shapiro-Wilk (normal), Kolmogorov-Smirnov (general).
- Gráficos de residuos: para modelos de regresión, los residuos deben ajustarse a la distribución de errores asumida.
Si se sospecha mala especificación, usa el bootstrap no paramétrico o el suavizado.
Cuándo usar el bootstrap paramétrico
El bootstrap paramétrico es la elección natural cuando:
- Existe un modelo distribucional bien justificado (exponencial para tiempos de espera, Poisson para recuentos, normal para errores de medición).
- La muestra es pequeña y el bootstrap no paramétrico tiene alta varianza.
- Se trabaja dentro de un marco de modelización (GLM, modelo de supervivencia, modelo mixto) donde la estructura paramétrica es parte de la inferencia.
- Se necesitan conjuntos de datos realistas para análisis de potencia o estudios de simulación.
💡 Bootstrap paramétrico en R
# Ejemplo exponencial
lhat <- 1 / mean(x)
boot_param <- replicate(2000, 1 / mean(rexp(length(x), rate = lhat)))
sd(boot_param) # EE bootstrap
quantile(boot_param, c(0.025, 0.975)) # IC al 95%
# Ejemplo de regresión
fit <- lm(y ~ x)
boot_beta <- replicate(2000, {
y_star <- fitted(fit) + rnorm(length(y), 0, sigma(fit))
coef(lm(y_star ~ x))[2]
})Para modelos complejos (GLM, modelos mixtos), la función simulate() de R genera muestras bootstrap paramétricas a partir de un objeto de modelo ajustado de forma automática.

