Método jackknife
El jackknife, introducido por Quenouille (1949) y ampliado por Tukey (1958), estima el sesgo y la varianza eliminando sistemáticamente una observación cada vez. Es anterior al bootstrap y es determinista: con los mismos datos siempre produce el mismo resultado. Para estadísticos suaves funciona bien; para estadísticos no suaves como la mediana puede fallar gravemente.
Algoritmo
Dada una muestra \(\mathbf{x} = (x_1, \ldots, x_n)\) y un estadístico \(\hat{\theta} = g(\mathbf{x})\):
- Para cada \(i = 1, \ldots, n\), calcula la estimación dejando uno fuera:
\[\hat{\theta}_{(i)} = g(x_1, \ldots, x_{i-1}, x_{i+1}, \ldots, x_n)\]
- Calcula la media jackknife:
\[\bar{\theta}_{(\cdot)} = \frac{1}{n} \sum_{i=1}^n \hat{\theta}_{(i)}\]
- Estima el sesgo:
\[\widehat{\text{Sesgo}}_\text{jack} = (n-1)\left(\bar{\theta}_{(\cdot)} - \hat{\theta}\right)\]
- Estima la varianza (y el error estándar):
\[\widehat{\text{Var}}_\text{jack} = \frac{n-1}{n} \sum_{i=1}^n \left(\hat{\theta}_{(i)} - \bar{\theta}_{(\cdot)}\right)^2\]
\[\widehat{\text{EE}}_\text{jack} = \sqrt{\widehat{\text{Var}}_\text{jack}}\]
El factor \((n-1)\) en la fórmula del sesgo y \((n-1)/n\) en la de la varianza son las correcciones jackknife que hacen que estos estimadores sean aproximadamente insesgados.
Ejemplo numérico completo
Estima la varianza del coeficiente de correlación muestral \(\hat{\rho}\) a partir de \(n = 8\) observaciones pareadas de estatura (cm) y peso (kg):
| \(i\) | Estatura | Peso |
|---|---|---|
| 1 | 170 | 65 |
| 2 | 182 | 78 |
| 3 | 165 | 60 |
| 4 | 175 | 72 |
| 5 | 168 | 63 |
| 6 | 178 | 75 |
| 7 | 172 | 68 |
| 8 | 180 | 80 |
Correlación original: \(\hat{\rho} = 0{,}992\).
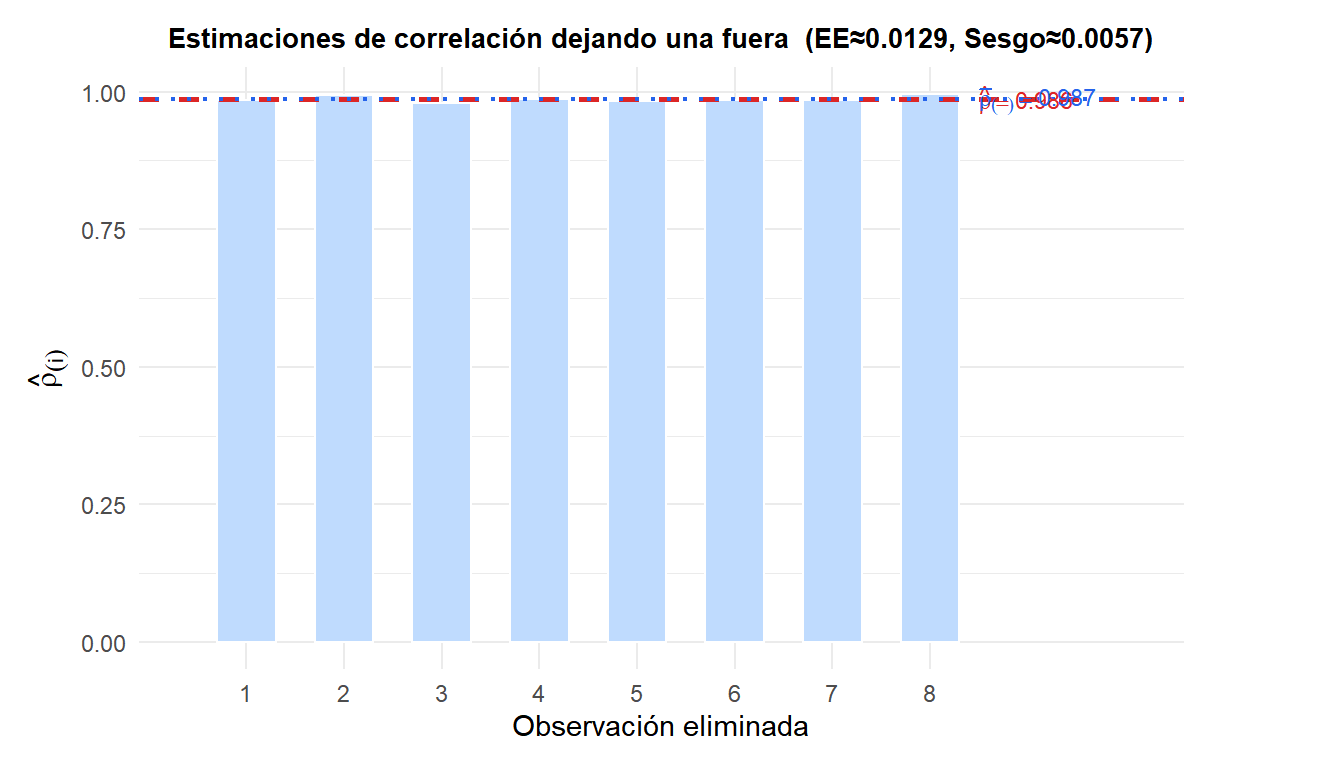
Las estimaciones dejando una fuera (barras) son todas muy próximas al \(\hat{\rho}\) de la muestra completa (rojo discontinuo), lo que confirma que la correlación es estable. El EE jackknife \(\approx\) 0.0129 y el sesgo \(\approx\) 0.0057.
Cuándo falla el jackknife: estadísticos no suaves
⚠️ El jackknife es inconsistente para estadísticos no suaves
El jackknife se basa en una aproximación lineal: asume que eliminar una observación cambia \(\hat{\theta}\) en una cantidad pequeña y suave. Para estadísticos no suaves (los que pueden cambiar de forma discontinua al añadir o eliminar una observación) esta aproximación se rompe.
El ejemplo clásico es la mediana muestral con \(n\) par. Eliminar una observación puede desplazar la mediana un intervalo entre observaciones completo en lugar de una pequeña perturbación. La estimación de varianza jackknife es entonces inconsistente: no converge a la verdadera varianza aunque \(n \to \infty\).
Estadísticos para los que el jackknife falla o funciona mal:
- Mediana muestral y otros cuantiles.
- Máximo y mínimo muestrales.
- Número de valores distintos en una muestra.
- Cualquier estadístico con una discontinuidad como función de los datos.
Para estos, usa el bootstrap.
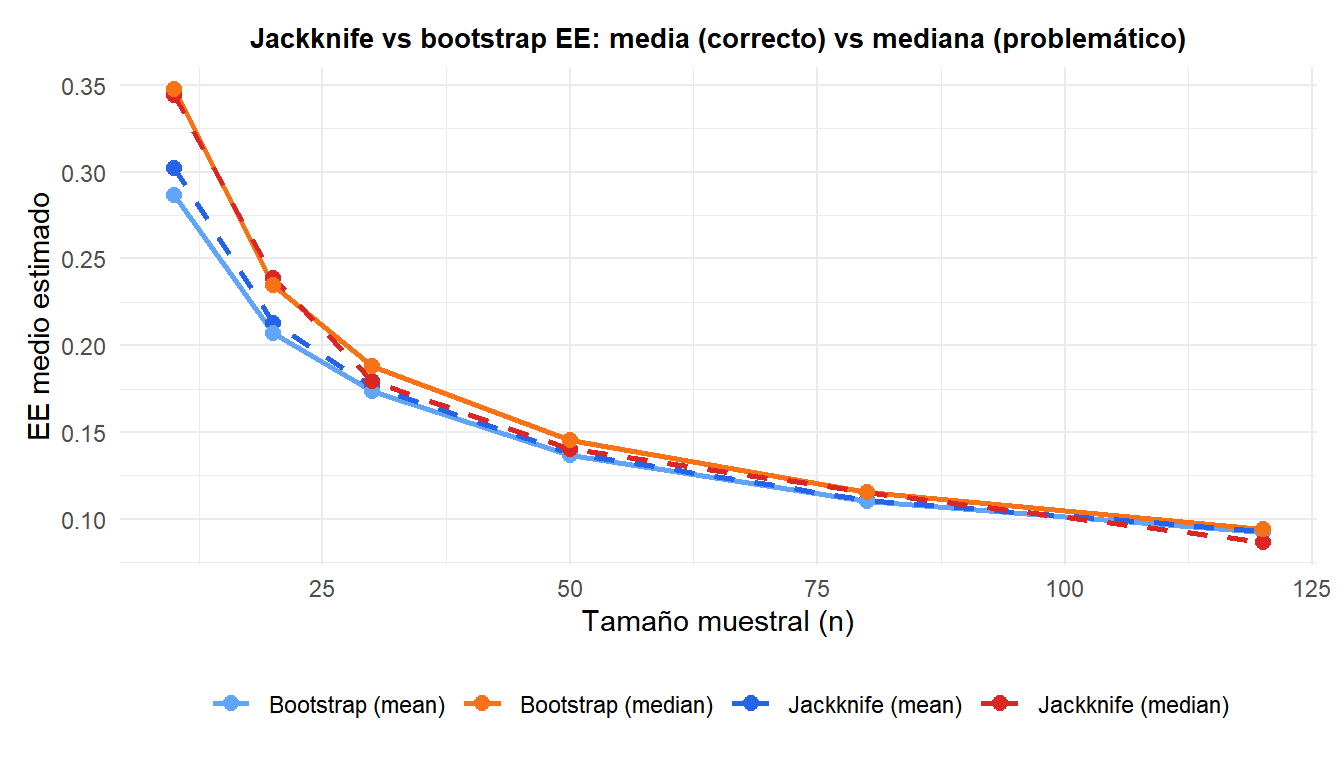
Para la media (tonos azules), el jackknife y el bootstrap dan estimaciones del EE similares en todos los \(n\). Para la mediana (rojo/naranja), el EE jackknife (rojo discontinuo) es errático y poco fiable, mientras que el EE bootstrap (naranja continuo) es consistente.
El jackknife de eliminación-\(d\)
El jackknife estándar elimina una observación cada vez. El jackknife de eliminación-\(d\) elimina \(d\) observaciones cada vez, creando \(\binom{n}{d}\) submuestras. Para \(d > 1\) puede manejar estadísticos no suaves:
\[\widehat{\text{Var}}_\text{jack-d} = \frac{\binom{n}{d}^{-1}}{n-d} \sum_{S} \left(\hat{\theta}_{(S)} - \bar{\theta}_{(\cdot)}\right)^2\]
donde la suma recorre todos los subconjuntos \(S\) de tamaño \(n-d\). El \(d\) óptimo para estadísticos no suaves satisface \(d/n \to 1\) cuando \(n \to \infty\). En la práctica, el bootstrap casi siempre se prefiere al jackknife de eliminación-\(d\) para estadísticos no suaves.
Jackknife vs bootstrap
| Jackknife | Bootstrap | |
|---|---|---|
| Submuestras | \(n\) (determinista) | \(B\) (aleatorio) |
| Aleatoriedad | Ninguna | Sí (Monte Carlo) |
| Estadísticos suaves | Excelente | Excelente |
| Estadísticos no suaves | Falla | Funciona |
| Coste computacional | \(O(n)\) evaluaciones | \(O(B \cdot n)\) |
| Corrección del sesgo | Fórmula directa | Requiere BCa u otro |
| Uso histórico | Anterior a 1979 | Posterior a 1979 (Efron) |
El jackknife es el predecesor del bootstrap y sigue siendo útil para estadísticos suaves, donde su naturaleza determinista (sin aleatoriedad, sin necesidad de elegir \(B\)) es una ventaja. Para todo lo demás, el bootstrap es la herramienta estándar.
💡 Jackknife en R
# Jackknife EE manual para cualquier estadístico
jackknife_se <- function(x, stat_fn) {
n <- length(x)
loo <- sapply(1:n, function(i) stat_fn(x[-i]))
sqrt((n-1)/n * sum((loo - mean(loo))^2))
}
jackknife_se(x, mean)
jackknife_se(x, var)
# La función bootstrap::jackknife()
library(bootstrap)
jackknife(x, mean)
